
Paylaş

SQL Server ile ilgili (pek) bilinmeyenler

1) sp_help bir sistem stored procedure’ü olup nesneler hakkında ayrıntılı bilgi almak için kullanılır.
2) Değer girilmemiş (NULL) olan ifadeler, gruplamalı fonksiyonlar için bir istisna olarak ele alınır.
Örneğin, SELECT MIN (price) FROM tblUrun sorgusu, en küçük ifade, fiyatı girilmemiş olan ürün gibi düşünmemize rağmen, NULL değeri döndürmez, girilmiş olan en küçük değeri döndürür.
3) İki tablo birbiri ile birleştirilerek sorgulanıyorsa (join) bu iki tabloyu farklı disklerde saklamak, seçme yapmak için geçen süreyi kısaltır.
4) Bir veritabanı tarafından kullanılan bir dosya, başka bir veritabanı tarafından daha kullanılamaz.
5) Veri ve transaction log bilgileri asla ortak bir dosyada yer alamaz.
6) Sp_spaceused sistem procedure’ü kullanarak veritabanındaki dosyaların doluluk oranları gibi özet bilgilere erişilebilir.
7) Transaction log dosyasının boyutu, Indeks ile ilgili değişiklikler yapıldığında ya da WRITETEXT,UPDATETEXT ile metin veya resim yazılırken, WITH LOG parametresi ile kullanılırsa artar.
8) Bir veritabanının boyutunu azaltma işini otomatik olarak SQL SERVER’a yaptırabiliriz (AUTO_SHRINK özelliği ile)
ALTER DATABASE veritabani ismi SET AUTO_SHRINK ON
9) Veri tabanını silmeden önce Master veri tabanının bir kopyasını almak, daha sonrası için yarar sağlayabilir.

10) IDENTITY fonksiyonu ile elde edilen değerin, her zaman tablo başına tekilliği garanti edilemez. Bu türden bir amaç için, Constraint ile ya da doğrudan unique index tanımlamak gerekir.
11) IDENTITY fonksiyonu ile üretilen primary key için üretimden sonra hata oluşursa bir sonraki seferde aynı sayı kullanılmaz. Bu nedenle, primary key’ler arasında açıklıklar kalabilir.Bu türden bir durumu toleransı olmayan durumlarda NEWID() fonksiyonu ile UNIQEIDENTIFIER türü ikilisinin kullanılması önerilir.
12) Çok güncellenen veriler XML olarak saklanmamalıdır.
13) Bir tabloya, kayıt girildikten sonra sütun eklenecekse, bir sütun NOT NULL ile tanımlanırken dikkatli olmak gerekir. Hesaplanmış sütun veya default değer tanımlanması olmadan bu işlem gerçeklenemez.
14) Foreign key Constraint ile ilişkilendirilmiş iki tablodan, foreign key’in bulunduğu tablo üstünde bir kullanıcının değişiklik yapabilmesi için birincil tarafa en azından SELECT ve REFERENCES hakkında verilmesi gerekir.
15) Foreign key ile sağlanan veri bütünlüğü, sadece bir veritabanı içerisinde tanımlanabilir. Farklı iki veritabanıdaki tablolar arasında veri bütünlüğü sağlayabilmek için Trigger kodlamak gerekir.
16) Her zaman where koşuluna sütunları kapsayan şartlar vermek zorunluluk değildir. Bir sorguda öylesine şartlarda verilebilir. (where 1=1 deyimi, arama yapmak üzere dinamik SQL oluşturulurken takip eden şartların sayısı bilinmediğinde ilerlemek için kullanılan bir yöntemdir.)
17) Order By kullanılırken, sıralamaya katılan sütunların seçilen sütunlardan olması gerekmez bunun aksine türetilmiş sütunlarda sıralamada kullanılabilir.
18) Sütunlara verilen takma adlara Order by tarafından erişilemez.
19) Tarih alanları sorgularken format problemi çekmemek için YYYY-AA-GG SS:DD:ss şeklinde string olarak istediğiniz tarihi vererek tarih kıyaslaması yapabilirsiniz.
20) SQL server’da bir sorgunun sonucu türetilmiş tablo olarak kullanılacaksa (sub query) hesaplanmış bütün sütunlara bir takma ad verilmelidir.
21) Join ifadeleri, sorgu veya tablo sonuçlarını yatay olarak birleştirmek maksatlı kullanılır. Düşey birleştirme için UNION deyimi kullanılır.
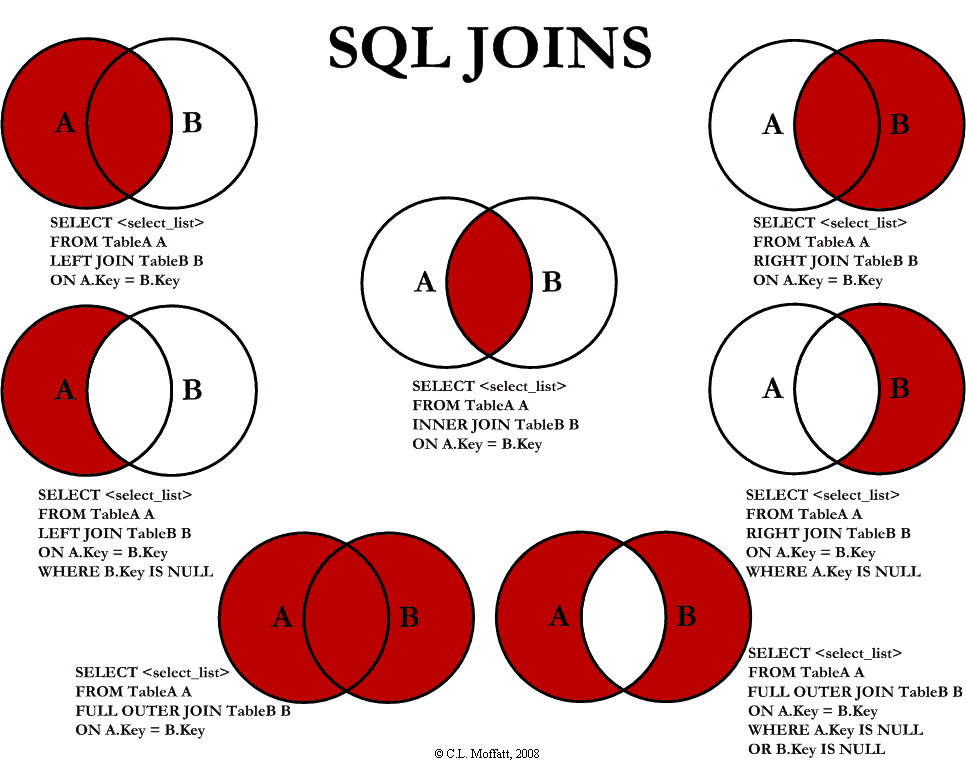
22) INNER ifadesi yer almadan sadece JOIN ifadesi kullanılırsa, SQL Server bunu Inner Join olarak yorumlar.
23) Cross join, birinci tabloda yer alan her bir kaydı ikinci tabloda yer alan her bir kayıt ile ilişkilendirerek satırlar türetmede kullanılır.
24) Union ifadesi ile birleştirilen iki resultset’ı aynı sıradaki sütunların adları farklı ise, geçerli sütun adı, ilk resultset’teki sütun adıdır.
25) Alt sonuçların varlığını kontrol etmeye yarayan IN,NOT IN,EXIST ve NOT EXIST yardımı ile de tek sütunluk sorgular kesişim ve fark işlemine tabi tutulabilir.Ancak birden fazla sütun olması durumunda bu deyimler bir işe yaramayacaktır.Bu tür durumlarda INTERSECT ve EXCEPT deyimlerinin kullanılması gerekir.
26) Bir sorguda, gruplamaya girmeden önce elenecek satırları WHERE cümleciği ile tanımlamak gerekir. Gruplama neticesinde türetilen satırlar üstünde filtreleme yapılacaksa, bu filtreleme işlemi için HAVİNG kullanılır.
27) Bir View’i silip yeniden oluşturduğumuzda, üstündeki izin ve engellemeleri yeniden ayarlamak gerekir. Ancak bir View Alter komutu ile değiştirilirse, hakların yeniden verilmesine gerek yoktur.
28) Non-Clustered indekslerin performansları, Clustered indekslerin performanslarından daha düşüktür.
29) Ondalıklı değişken değerler için kullanılabilecek değişken tiplerinden MONEY, DECIMAL gibi değişken tiplerinin tercih edilmesi önerilir, FLOAT değişken tipi kesin değer döndermediği için kullanılması pek tercih edilmez.
30) Unicode değişken tipleri, gereksiz yer tutması sebebiyle çok gerekmediği durumlarda kullanılması pek tercih edilmez (nvarchar, nchar gibi).
31) TEXT değişken tipi 2gb’a kadar yazıları tutabilir, adres değerini tuttuğu için Update, Insert işlemleri yaptığımız zaman işlem yapmaz, onun için ayrı bir kod yazmak gerekir.
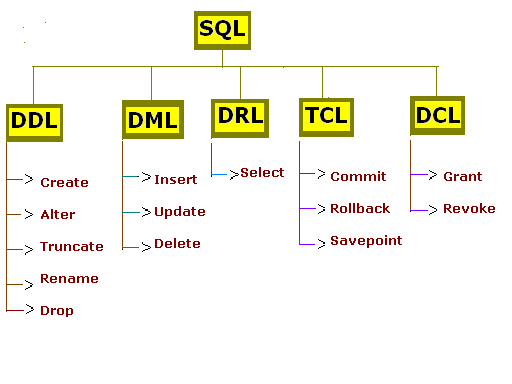
32) DDL (CREATE, ALTER, DROP) Objectle ilgili yaptığımız her işlem için kullanılır. (schema, function, stored procedure vs.)
33) DML (DELETE, INSERT, UPDATE, SELECT, TRUNCATE) Data ile ilgili yaptığımız her işlemdir.
34) Yarattığımız Stored Procedure’ün değerini değiştirmek istediğimizde artık ALTER TABLE etmeliyiz, aksi taktirde Create ifadesi ile zaten oluşturduğumuz stored procedure’ü tekrar oluşturmaya çalıştığımız için hata alırız.

35) Tablo üzerinde yapılacak her türlü fiziksel değişiklik ALTER TABLE ile yapılır.
36) SELECT TOP 0 * INTO komutu tablonun direkt kendisini yaratır; ama keyleri kaybederek yaratır.
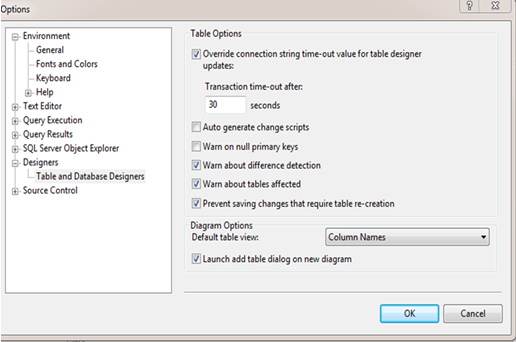
37) Veri tabanında oluşturduğumuz bir tabloda üzerinde herhangi bir değişiklik yapıp sonra da kaydetmek istediğimizde, sonradan yapacağımız değişikliklere izin verilmez.
Bu durumu aşmak için,
Tools > Options > Prevent saving changes that require table re-creation checkbox’ında seçili olarak gelen işareti kaldırıp save edebiliriz.
38) Bir SP’nin bittiği yerde go deyimini kullanmak, sp’nizin bittiği yeri tam olarak belirtmenizi sağlayacağından istemediğiniz kodların sp ile birlikte derlenmesine ve istenmeyen hatalar meydana getirmesine engel olur.
Temel veritabanı nesneleri hakkında küçük hatırlatmalar:
ResultSet (Sonuç kümesi):
Bir seçme işlemi gerçekte veri tabanın da olmayan bir tablo döndürür. Bu tablo bazen 1 satır ve 1 sütundan oluşur.
Constraint (Kısıtlayıcı):
Herhangi bir alan için girilebilecek verileri zorlayıcı kurallara Kısıtlayıcı denir. Primary Key, Uniqe Key, Foreign Key gibi. Veritabanına kullanıcının keyfi değerler girmesi önlenmiş olur.
Indeksler:
Bir kaç yüz kayıttan oluşan bir tablo üstünde kayıt arama işlemi, VTYS için oldukça basit bir işlemdir ancak bu sayı milyonlara çıktığında doğru verilere erişmek için fazla zamana ihtiyaç duyulur. Bu nedenle verileri çeşitli özelliklerine göre organize edip sıralayacak ve bu sayede daha hızlı erişmemize olanak tanıyacak yapılara ihtiyaç duyarız. Indexler, kayıtları fiziksel olarak sıraya sokuyorsa CLUSTERED INDEKS, fiziksel olarak sıraya koymuyorsa NONCLUSTERED INDEKS adını alır.
Clustered INDEKS:
Verilerin kendisinin index key (indexin verileceği kolon) değerine göre fiziksel olarak alfabetik sıralandığı index türüdür. Clustered Index bir tabloda maksimum bir tane olabilir. (Örnegin telefon defterinde yapılan bir arama)
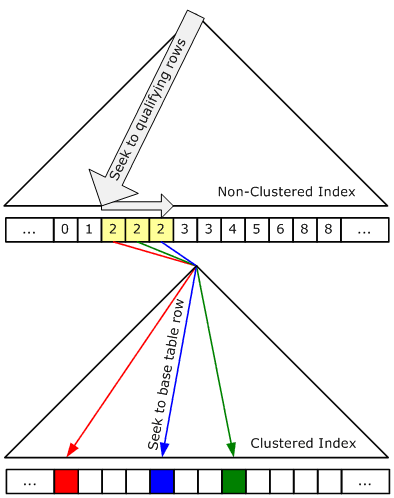
Non-Clustered Index:
Non-Clustered Index mimarisinde fiziksel bir sıralama söz konusu değildir. Index değeri, Clustered Index’in aksine verinin kendisi değil pointer değeridir. Bu pointer değeri verinin nerede olduğunu gösterir. Non-clustered Index bir tabloda maksimum 999 tane olabilir.(Sql Server 2008 için) (Örneğin Kitap’ta sayfa numaralarına göre yapılan bir arama )
CREATE NONCLUSTERED INDEX IX_LastName_FName_MName on Person.Person (LastName, FirstName, MiddleName)
Schema yaratma:
Aynı isimde tablo, stored procedure gibi nesneleri farklı şemalar içerisinde yeniden tanımlayabilmek mümkündür.
Create schema Pinar create table pinar.depertmant ( ID int identity (1,1), Ad varchar (50) ) Select * from pinar.depertmant
View:
Bazen tabloları olduklarından farklı gösterecek filtrelere ihtiyaç duyarız. View’lar birden fazla tablodan daha kolay veri almak için kullanılır. Program içinde yazılan kod daha basit olur. Yine tablolardaki bazı sütunlar gizlenebilir. Oluşturulan View’e bu sütun koyulmayabilir. View’ler bir çeşit istatistik olarakta kullanılabilir.
View’ler sonuç itibari ile gerçek anlamdaki tablolar değildir. Bundan dolayı View’ler üstünde ekleme veya güncelleme yaparken çeşitli kısıtlamalar vardır. Aslında bize direk select sorgusunu getirir. Update, Insert, Truncate işlemleri yapamazsın. View oluşturulduğunda, yapılabilecek herhangi bir hata da geri alınabilir. Ancak her View den select çektiğinde db.de performans sorunu yaratabilir.
select * from HumanResources.vEmployee
şeklinde gösterilir.
Stored Procedure:
Genellikle veritabanı uygulamalarında veri erişim katmanı olarak kodlanır. Dışardan parametre alabilirler ve dışarıya parametre resultset döndürebilirler.
1.Datalar üzerinde yapacağın işlemleri saklı yordamlarda saklayabilirsin . Her gece kendisinin çalışmasını istediğin kod parçalarını Strod procedure yazarak sağlayabilrsin.
2.Jop’larla çalışma sürelerini ayarlayabilirsiniz.
3.Stored’lerin execute edilmesi gerekir. Tekrardan select * from sp yazmanıza gerek yoktur, zaten içinde select cümleleri saklıdır.
Function:
0-1 ya da yes-no şeklinde değerler döndürür .İstenildiği takdir de Table ‘da döndürebilir. Parametre alabilir (@PersonID int) gibi .
ALTER FUNCTION [dbo].[ufnGetContactInformation](@PersonID int)
RETURNS @retContactInformation TABLE
(
-- Columns returned by the function
[PersonID] int NOT NULL,
[FirstName] [nvarchar](50) NULL,
[LastName] [nvarchar](50) NULL,
[JobTitle] [nvarchar](50) NULL,
[BusinessEntityType] [nvarchar](50) NULL
)
Truncate ile Delete işlemleri arasındaki farklar
- TRUNCATE komutu ile parçalı silme yapılamazken DELETE komutu ile WHERE clause kullanılarak parçalı silme yapılabilmektedir.
- DELETE komutu ile yapılan kayıt silme işleminde her silinen kayıt Transaction Log da kayıt bazında loglanmaktadır. TRUNCATE de ise loglama işlemi kayıt bazında yapılmamaktadır. Bu yüzden TRUNCATE komutu DELETE komutuna oranla büyük tablolarda inanılmaz hızlıdır.

- Eğer silme yapılan tabloda identity column var ise, TRUNCATE işleminden sonra bu kolon 1 den başlamakta, DELETE işleminden sonra ise kaldığı yerden devam etmektedir.
- Foreign key içeren tablolarda TRUNCATE işlemi yapılamaz. Çünkü Foreign key’e bağlı olan kayıtlarında silinebilmesi için table’ın trigerlanması gerekmekte ama TRUNCATE işleminde daha öncede söylediğim gibi loglama işlemi gerçekleşmemektedir. Genede TRUNCATE kullanmak istiyorsanız önce Foreign key in kaldırılması sonra TRUNCATE in yapılması ve daha sonrada Foreign Key in tekrar tanımlanması gerekmektedir.
- Foreign key içeren tablolar DELETE ile silinmek zorundadır ya da performanslı olmasını istiyorsanız işlemi DROP-CREATE şeklinde gerçekleştirebilirsiniz.
Primary Key oluşturma:
Create table Musteri ( MusteriID int identity(1,1) not null, Ad nvarchar(50), Soyad nvarchar(50) Constraint PK_Musteri Primary key clustered (MusteriID ASC) )
Foreign Key oluşturma:
- Hareket tablolarından özet tablolara referans alır.
- Kendisine baglı özet tabloların primerykeylerini tutar.
- Foreign key hareket tablolarıdır,bunlar verilerin çok olduğu sürekli değişimin olduğu tablolardır. (Siparis Tablosu gibi)
Sonradan foreign key eklemek isterseniz yani tablo oluştuktan sonra,
CREATE table Musteri ( MusteriID int identity(1,1) not null, Ad nvarchar(50), Soyad nvarchar(50) Constraint PK_Musteri Primary key clustered (MusteriID ASC) ) Create table Siparis ( SiparisID INT identity(1,1) not null, MusteriID INT not null, Primary key (SiparisID), Constraint PK_Musteri FOREIGN KEY (MusteriID) REFERENCES Musteri(MusteriID) ) ALTER TABLE dbo.Siparis ADD CONSTRAINT FK_Musteri FOREIGN KEY (MusteriID) REFERENCES Musteri(MusteriID)
Unique Key:
Bir alanı Unique yaptığınızda onu eşsiz yapmış olursunuz, mesela email alanını unique yaptığınızda ikinci kez aynı emaili eklemek istediğinizde veritabanı hata verecektir. Her eklenen email bir kez eklenebilir ve veritabanında böylelikle tektir.
Örneğin müşteri kodu P423423 şeklinde string bir ifadeniz olsun, siz bunun tekil (primary key )olmasını istiyorsananız, bu bir string olduğu için sorun yaratabilir, ama Unique key derseniz sıkıntı çıkmaz .
PR – Key’ide Unique gibidir bir alani eşsiz yapar ama farkı bir tabloda sadece bir tane primary key olmasıdır.
Null değerlerde alabilir. Örneğin müşteri tablosundaki TCKN gibi uzun bir alana primery key de koymak istemiyorsanız, o zaman UK yapabilrsiniz.
Sub Query:
Sub Query yani sorgu içinde sorgu, içteki sorgunun dışta olan sorguya değer üretmesidir. BO tarafında kullanımı daha fazladır .
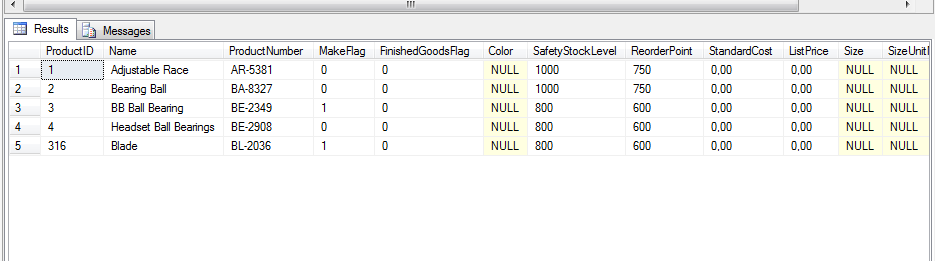
select * from (select TOP 10 * FROM AdventureWorks2008R2.Production.Product) s WHERE s.Color is null
select * from Sales.Customer c inner join Person.Person p on c.PersonID = p.BusinessEntityID inner join (select CustomerID, TotalRevenue = SUM (LineTotal) from Sales.SalesOrderDetail SD inner join Sales.SalesOrderHeader SO ON SD.SalesOrderID = SO.SalesOrderID Group by CustomerID having SUM (LineTotal) > 5000 ) x on x.CustomerID = c.CustomerID
Sub – Query’ler performas açısından gerekmediği durumlarda fazla tercih edilmezler, bunun yerine Temp Table kullanmak daha iyi olur .
Temp Table:
Geçici tablolar çalışma anında oluşturulur ayrıca normal bir tabloda yapabileceğimiz tüm işlemleri temp tablolarda da yapabiliriz. Temp Tablolar tempdb veritabanında saklanırlar.

1) Local Temp Table
Local Temp tablolar sadece tabloyu oluşturan kullanıcının, oluşturmak için kullandığı connection üzerin de geçerlidir. Kullanıcı bağlantıyı kapattığı anda otomatik olarak silinir. Local Temp tablo tanımlamak için tablo isminin önüne # işareti koymamız yeterlidir.
2) Global Temp Table
Global olarak temp tablo tanımlamak için ## karakterlerini tablo isminden önce eklememiz yeterlidir. Global temp tablolar bir connection içinde tanımlandığı anda, normal tablolar gibi tüm kullanıcılar ve connectionlar içinde kullanılabilir hale gelirler. Global tabloyu oluşturduğunuz connection kapatılana kadar bu tablo var olmaya devam eder.
Local Temp Table örneği:
select CustomerID, TotalRevenue = SUM (LineTotal) INTO #CustomerTotalRevenue from Sales.SalesOrderDetail SD inner join Sales.SalesOrderHeader SO ON SD.SalesOrderID = SO.SalesOrderID Group by CustomerID having SUM (LineTotal) > 5000 SELECT p.* from Sales.Customer c inner join Person.Person p on c.PersonID = p.BusinessEntityID inner join #CustomerTotalRevenue x on x.CustomerID = c.CustomerID
Temp Table oluşturmanın bir diğer yöntemi ise tek sefer kullanım hakkı olan Memory’de bir Table yaratmak.
;WITH CustomerTotalRevenue AS ( select CustomerID, TotalRevenue = SUM (LineTotal) from Sales.SalesOrderDetail SD inner join Sales.SalesOrderHeader SO ON SD.SalesOrderID = SO.SalesOrderID Group by CustomerID having SUM (LineTotal) > 5000 ), top5 AS ( SELECT TOP 5 * from CustomerTotalRevenue ) DECLARE @CustomerTotalRevenue TABLE ( CustemerID int, TotalRevenue decimal (18,5) ) INSERT INTO @CustomerTotalRevenue select CustomerID, TotalRevenue = SUM (LineTotal) from Sales.SalesOrderDetail SD inner join Sales.SalesOrderHeader SO ON SD.SalesOrderID = SO.SalesOrderID Group by CustomerID having SUM (LineTotal) > 5000 --DECLARE @CustomerTotalRevenue TABLE --( --CustemerID int, --TotalRevenue decimal (18,5) --) Once tabloyu declare etmeliyiz daha sonra burayi kaldirip tum sorguyu calistirmaliyiz. Select * from @CustomerTotalRevenue
Veri Ambarı Şemaları
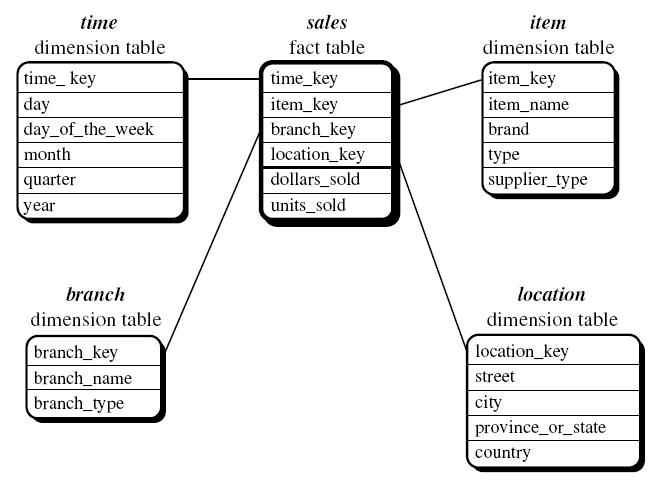
1) Star SCHEMA
- Bu şema yapısı en sık tercih edilen şema modelidir. Merkezde konumlandırılmış bir fact table ve onun etrafını sarmış dimension table’ların bir yıldız şeklini anımsatmasından dolayı da Star Scheme (Yıldız Şema) adını almıştır.
- Bu şema yapısında fact table ‘a keylerle bağlanmış olan dimension tablelar demormalize edilmiştir.
- Fact tablolarda, dimension tabloların primery keyleri ve sayısal değerler tutulur.
- Her dimension tablodan fact tabloya bir bağlantı gelir.
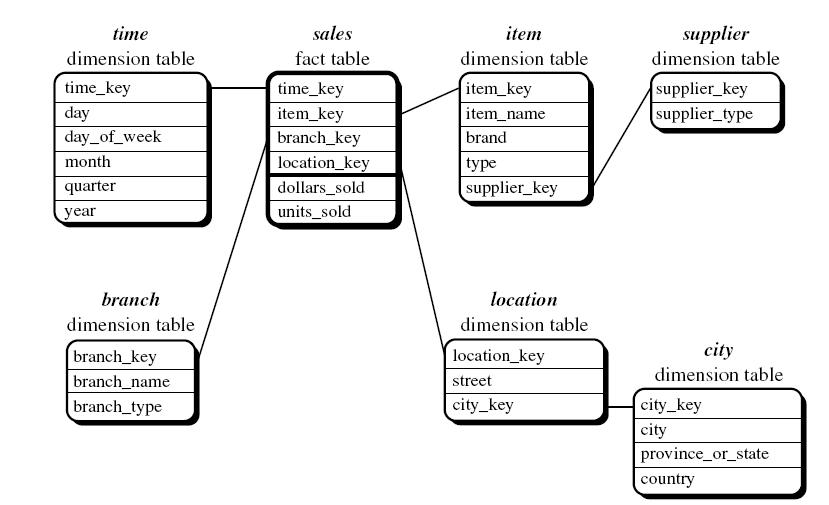
2) Snowflake SCHEMA
- Bu şema yapısındaysa; merkezde konumlandırılmış bir fact table ve onun etrafını sarmış dimension table’lara bağlanmış başka dimension table’ların kar tanelerine benzer bir şekil oluşturmasından dolayı Snowflake Schema denmiştir.
- Bu şema yapısında fact table ‘a keylerle bağlanmış olan dimension tablelar normalizasyon kurallarına göre dizilmişlerdir, zaten dimensionlara bağlı başka dimensionlar olması da normalizasyon kurallarına uymak içindir.
- Özet tablonun da bir özetini çıkarıyoruz. Buna da bir foreıgn key tanımlıyoruz .
- Sorgu performansını artırır.
Normalizasyon nedir?
Verilerin düzenli olarak tutulmasını sağlayan kurallar topluluğudur. Çıkarabildiğimiz kadar farklı varyasyonlar için düzeltme temizleme yapılabilir. Data tekrarını önlemek, verilerin kapladğı alanları azaltır.



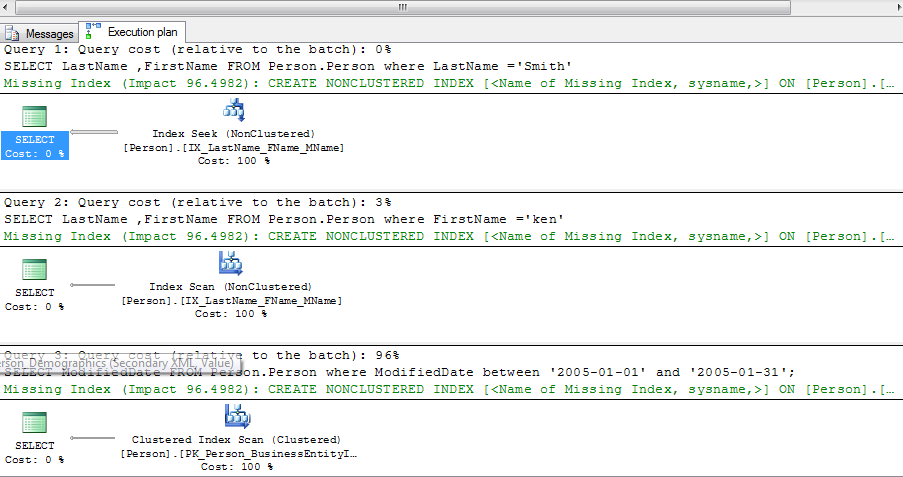
Performans karşılaştırmasını nasıl görebiliriz?
Performans karşılaştırması yapmak için Display Estimated Execution Plan butonuna tıkladıgımızda, cost’tan nerede ne kadar zaman harcadıgını görebiliriz.
Örneğin,
SELECT LastName,FirstName FROM Person.Person where LastName ='Smith' SELECT LastName,FirstName FROM Person.Person where FirstName ='ken' SELECT ModifiedDate FROM Person.Person where ModifiedDate between '2005-01-01' and '2005-01-31';
Merge komutunun kullanımı
Update, insert gibi komutları bir arada conditiona bağlı olarak yapıldığı, eşleşen kayıt varsa update et, kayıt yoksa insert et işlemlerini yapmak için kullanırız.
Olan kaydı update edersin, source içinde yoksa insert edersin.
MERGE INTO tablename USING table_reference ON (condition) WHEN MATCHED THEN UPDATE SET column1 = value1 [, column2 = value2 ...] WHEN NOT MATCHED THEN INSERT (column1 [, column2 ...]) VALUES (value1 [, value2 ...
Örneğin,
MERGE #product tgt USING ProductWellDone src ON src.ProductID = tgt.ProductID WHEN MATCHED THEN UPDATE SET tgt.HasAferin = 'Yes' WHEN NOT MATCHED BY SOURCE THEN DELETE ;
Hadi bir de örneklere göz atalım!
1. Cursor kullanımı:
USE dukkan GO -- oncelikle scroll cursor'umuzun sececigi ifadeyi görelim: SELECT markaKod, marka FROM tblMarka ORDER BY markaKod -- Scroll cursor tanımlayalım. DECLARE crScrMarka SCROLL CURSOR FOR SELECT markaKod, marka FROM tblMarka ORDER BY markaKod OPEN crScrMarka -- cusror'un son satirina gidelim: FETCH LAST FROM crScrMarka -- anlik olarak ilk kayda gecelim: FETCH PRIOR FROM crScrMarka -- bastan 2.kayda konumlanalim: FETCH ABSOLUTE 2 FROM crScrMarka -- bulundugumuz yerden 3 kayit ileri konumlanalim: FETCH RELATIVE 3 FROM crScrMarka -- bulundugumuz kayittan 2 kayit geriye konumlanalim: FETCH RELATIVE -2 FROM crScrMarka CLOSE crScrMarka DEALLOCATE crScrMarka GO
2. Tablo tipi parametre kullanım örneği:
--- 1. Daha onceden tanimlanmamissa once tablo tipini tanımlayalim. CREATE TYPE dbo.MarkaTip AS TABLE( markaKod INT, marka VARCHAR(50) ); GO -----2.. Tablo alan Stored Procedure kodlanmasi ALTER PROC _SP_BelliMarkaUrunlerSec(@markaTablo AS dbo.MarkaTip READONLY ) AS BEGIN SELECT U.urunKod,U.urunAd,M.marka FROM tblUrun U JOIN @markaTablo M ON U.markaKod=M.MarkaKod END GO --- 3.simdi de kullanalim.... --Once girdi parametreyi olusturup dolduralim DECLARE @marka AS dbo.MarkaTip; INSERT INTO @marka(markaKod,marka) SELECT TOP(9) markaKod,Marka FROM tblMarka; --sonra stored Procedure'u secelim EXEC _SP_BelliMarkaUrunlerSec @marka GO
3. Transaction örneği:
CREATE TABLE tblHesap(
HesapNo CHAR(10) PRIMARY KEY NOT NULL,
isim VARCHAR(55),
soyad VARCHAR(55),
sube INTEGER,
bakiye MONEY
) ;
INSERT tblHesap
VALUES('000000023','Ali','Eryatan',749,30000000);
INSERT tblHesap
VALUES('000000042','Ahmet','Eryatan',749,30000000);
-- Ali Ahmet'e 1000 lira havale yaparsa...
BEGIN TRAN
UPDATE tblHesap
SET bakiye=bakiye – 1000
WHERE hesapNo='000000023'
UPDATE tblHesap
SET bakiye=bakiye + 1000
WHERE hesapNo='000000042'
COMMIT
-- TRY-CATCH ile kullanilmali.
4. Veritabanı yetkinliklerini artırma – yedekleme ve yedekten döndürmek:
USE master; ALTER DATABASE dukkan SET RECOVERY FULL ; BACKUP DATABASE dukkan TO DISK='D:\yedekler\dukkan.bak'; ha BACKUP DATABASE dukkan TO DISK='D:\yedekler\dukkan.bak' WITH INIT; SELECT b.backup_set_id yedekno, b.media_set_id medya_no, b.database_name veritabani, f.logical_name ad, f.file_type yedekTip FROM backupset b LEFT JOIN backupfile f ON b.backup_set_id = f.backup_set_id RESTORE DATABASE [dukkan3] FROM DISK = N'D:\Yedek\dukkan.bak' WITH MOVE 'dukkan_Data' TO 'D:\SQLData\2008_dukkan\dukkan3.MDF', MOVE 'dukkan_Log' TO 'D:\SQLData\2008_dukkan\dukkan3_1.LDF' USE msdb ; SELECT backup_set_id, media_set_id, position, name, type FROM backupset WHERE name LIKE 'dukkan-%' ; RESTORE DATABASE [dukkan] FROM DISK= 'D:\Yedek\dukkan.bak' WITH FILE = 1, NORECOVERY ; RESTORE LOG [dukkan] FROM DISK= 'D:\Yedek\dukkan.bak' WITH FILE = 2,NORECOVERY ; USE msdb ; SELECT backup_set_id, media_set_id, position, name, type,backup_start_date,backup_finish_date FROM backupset WHERE name LIKE 'dukkan-%' -- Belli bir zamana donmek RESTORE DATABASE [dukkan] FROM DISK= 'D:\Yedek\dukkan.bak' WITH FILE = 1, STOPAT='2010-06-28 00:00', NORECOVERY ; RESTORE LOG [dukkan] FROM DISK= 'D:\Yedek\dukkan.bak' WITH FILE = 2, STOPAT='2010-06-28 00:00', NORECOVERY ; RESTORE LOG [dukkan] FROM DISK= 'D:\Yedek\dukkan.bak' WITH FILE = 3, STOPAT='2010-06-28 00:00', NORECOVERY ; RESTORE LOG [dukkan] FROM DISK= 'D:\Yedek\dukkan.bak' WITH FILE = 4, STOPAT='2010-06-28 00:00', RECOVERY ;
Aklınızdakileri hayata geçirebilmeniz dileğiyle, sevgilerle…
 – What is ASO in Marketing?")

: Kendi Bilgisayarında Minecraft Sunucusu Kurma Rehberi")
Normalizasyon konusu tam olarak kafamda canlanmadı, biraz daha detaylı anlatabilir misiniz? Hep kafama takılan bir konu 🙂